
De l'ADN moléculaire à l'ADN vibratoire
1. La molécule d'ADN et le code génétique
Alain Boudet
Dr en Sciences Physiques
 1. La molécule d'ADN et le code génétique
1. La molécule d'ADN et le code génétiqueRésumé: De la cellule aux gènes, en passant par les chromosomes et l'ADN, vous êtes invités à visiter les rouages du programme génétique qui commande notre développement physique. Comment fonctionne-t-il? Jusqu'à quel point nous contrôle-t-il? Quel est son langage? Vous pourrez le découvrir sans notion de biologie ou de chimie en observant le paysage, tel un voyageur qui s'aventure dans le monde des molécules.
Dans quelle mesure notre vie et notre développement physique sont-ils gouvernés par la génétique et par l'ADN? Il est fréquent d'entendre parler de code génétique, de maladie héréditaire, de tests ADN, etc. Mais savez-vous de quoi il s'agit? A quoi sert l'ADN? Comment fonctionne-t-il?
Nous entendons parfois parler de ces choses, à l'école ou à la télé, et nous répétons sans vraiment comprendre. Dans cet article, vous découvrirez l'ADN comme vous découvrez un pays, avec des sensations visuelles, à partir de questions qui nous concernent. Peut-on décrire le monde de l'ADN sans employer un langage scientifique spécialisé? Je pense que oui et c'est ce que j'ai tenté de réaliser. Vous trouverez peu de descriptions biologiques et chimiques dans ce texte. De telles descriptions sont disponibles dans de nombreux sites, dont certains, riches et bien construits, sont cités en fin de page.
Nous habitons dans un corps, mais nous n'avons pas le sentiment de l'avoir choisi comme on choisit ses vêtements ou sa voiture. Quelquefois nous sommes fiers de lui, et quelquefois nous aurions voulu qu'il soit différent. Nous ne contrôlons pas sa forme, sa taille, la couleur de nos cheveux, pas plus que le genre masculin ou féminin, ni la façon dont il fonctionne. Bien entendu, nous sommes responsables des soins que nous lui prodiguons et de son entretien, mais la base anatomique et biologique de notre corps échappe à notre volonté et à notre contrôle.
Alors quel est le poste central qui définit toutes ses caractéristiques et la façon dont il se développe? Nous avons la sensation que notre corps est dirigé par une sorte de programme de développement biologique interne qui comporte un plan de construction avec son calendrier de réalisation. Ceci est vrai pas seulement pour l'être humain, mais pour l'ensemble des êtres vivants.
L'observation des êtres vivants quels qu'ils soient montre qu'ils se développent selon un plan bien établi. C'est à partir d'une seule graine que les végétaux croissent et deviennent plante, arbuste, ou arbre d'une espèce bien déterminée, un organisme complet et complexe qui comporte toutes les fonctions nécessaires à sa vie. Tous les chênes d'une même espèce se développent selon le même "patron", le même schéma. Ce schéma contient leurs caractéristiques qui les font reconnaitre comme des chênes: hauteur, aspect de l'écorce, forme des feuilles, durée moyenne de vie, etc. C'est la même chose pour les animaux et pour l'être humain qui se développent selon des caractéristiques propres à leur espèce à partir d'une seule cellule.
La manière dont ce programme de développement est inscrit est appelé le code génétique. Génétique, cela signifie qui engendre, génère, donc crée. Ce code a-t-il un support physique? Est-il écrit quelque part dans l'organisme? OUI. Selon nos connaissances actuelles, le programme biologique de développement est écrit dans l'ADN, avec une écriture qu'on nomme justement le code génétique et qui a son langage propre.
Pour faire connaissance avec l'ADN et le code génétique, nous allons d'abord suivre les traces des naturalistes et biologistes qui l'ont découvert puis examiné et relater quelques observations scientifiques qui ont permis d'en arriver à ces conclusions. Cela nous permettra également de mieux nous rendre compte de la façon dont progressent nos connaissances: sous forme fragmentaire, par le recoupement d'observations précises dans des domaines spécialisés, toujours susceptibles d'être remises en cause ou intégrées dans des visions plus larges.
Vous savez probablement que les molécules d'ADN habitent au cœur des cellules, et nous allons donc commencer par visiter des cellules. Cellule, un mot courant, une notion répandue, tout le monde sait que notre corps est constitué de cellules. Mais réfléchissez deux minutes. Comment le savez-vous, vous? Quelle idée vous faites-vous d'une cellule? Quelle taille? Comment fonctionne-t-elle? Comment les cellules sont-elles disposées dans votre corps? Se poser la question, c'est déjà presque avoir la réponse, car notre ignorance résulte souvent du fait que nous n'avons jamais porté notre attention sur cet aspect de notre vie. Faisons-le.
Observez votre peau. Voyez-vous des cellules? Non, car elles sont trop petites pour être détectées à l'œil nu. Pour les découvrir, nous devons les regarder avec l'aide d'un microscope. Et c'est justement ce qu'ont fait des pionniers à une époque où les lentilles de verre n'étaient pas fabriquées par une micromécanique contrôlée électroniquement avec des plans conçus par ordinateur comme maintenant. Vous connaissez sans doute ce genre de personnes, éventuellement par le film ou le roman, qui sont quelquefois des adolescents, des passionnés qui sont avides de réponses à leurs interrogations et sont poussés par leur curiosité insatiable à imaginer des appareils pour comprendre.
Ce sont des hommes de ce genre qui ont inventé et perfectionné le microscope (scope = regarder; micro = le tout petit). Ainsi l'anglais Robert Hooke et le hollandais Antony van Leeuwenhoek (1632 - 1723). Et c'est Hooke qui le premier a vu quelque chose qui ressemble à des cellules dans une écorce de liège et leur a donné ce nom de cellules, c'est-à-dire des petits compartiments. Il a publié ses travaux dans un livre, Micrographia, en 1665. De mon point de vue, cette remarque est intéressante parce qu'elle nous montre que la notion de cellule est relativement récente dans notre culture occidentale. Et d'autre part que notre connaissance est liée en grande partie à la mise au point d'appareils. Cependant, ces appareils sont le résultat direct de la pensée de ces hommes, donc de la façon dont ils veulent comprendre et expliquer.
 |
 |
| Fig.1- Microscope en argent fabriqué avant 1700 par Leeuwenhoek. Il est constitué d'une bille de verre enchâssée dans une plaque d'argent ou de cuivre. Taille: 45 mm de long | Fig.2- Microscope fabriqué vers 1820 par Robert Bancks. A l'étage intermédiaire, on distingue la lame de verre sur laquelle on déposait l'objet à examiner, comme on le fait encore. |
 |
 |
| Fig.3- Microscope optique actuel pour la recherche (Olympus) | Fig.4- Un microscope électronique à balayage (Philips) |
Depuis cette époque, les microscopes ont bénéficié des développements de l'optique et des procédés de fabrication des lentilles, de l'électronique et de l'informatique. Dans les années 1930, un nouveau type d'appareil a été inventé, le microscope électronique, avec lequel les objets sont observés en les "éclairant" non avec de la lumière, mais avec un faisceau d'électrons, d'où leur nom (voir également mon ouvrage sur les Microstructures des polymères photographiées avec des microscopes, et mon article Observer la matière en 3 dimensions). Ce sont ces appareils qui ont contribué à fournir de nombreux détails sur les cellules et sur l'ADN. Par ailleurs, ces observations ont été confrontées aux autres informations apportées par les méthodes biochimiques.
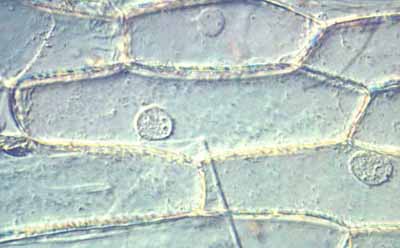
Au microscope, les cellules sont plus ou moins visibles. Nous regarderons celles qui sont les plus faciles à observer. C'est le cas de la pelure d'ognon [Non pas de faute, c'est l'orthographe recommandée depuis 1990]. Il faut aussi que le morceau de tissu observé soit une fine pellicule.
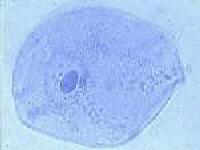
Sur l'image présentée ci-dessous à gauche, on voit nettement plusieurs cellules délimitées par des parois, collées les unes aux autres. A l'intérieur de chaque cellule, on détecte la présence d'une inclusion à peu près circulaire. C'est le noyau de la cellule. Il joue un rôle essentiel à cause de l'ADN qui s'y trouve, comme on va le voir. Il est délimité par une paroi souple, une membrane.
|
|
|
| Fig.5- Image de pelure d'ognon Assemblage de cellules délimitées par des parois. Noyaux visibles dans chacune d'elle Grossissement environ 600 fois Merci à Christian Loockx |
Fig.6- Image d'une cellule de la bouche Le noyau apparait en sombre Coloration au bleu de méthylène |
Notez que le noyau présente à peu près le même aspect, à l'œil, que le reste de la cellule. On ne peut le distinguer que parce que son contour a été renforcé visuellement. La façon dont on renforce les éléments à peine visibles d'une image est cruciale pour la découverte des structures internes de la cellule. Il existe de multiples façons d'obliger ces structures à se montrer en augmentant leur contraste visuel, mais elles relèvent de deux types de méthodes.
L'une consiste à agir sur l'éclairage de l'objet examiné et sur l'optique de formation de l'image. Cela a donné naissance à plusieurs variantes de microscopie (à contraste de phase, à contraste interférentiel comme dans l'image ci-dessus, à fluorescence, etc.).
L'autre consiste à injecter dans la cellule un colorant qui se répand partout, mais se fixe préférentiellement (avec une plus grande concentration) sur certaines parties, par exemple le noyau. Il existe plusieurs colorants employés couramment.
Examinons maintenant un tissu animal coloré avec une teinture bleue. C'est une cellule prélevée à l'intérieur de la bouche d'un humain. On distingue très bien le noyau, plus sombre. La taille de la cellule est d'environ 0,050 mm ou 50 micromètres (µm). La paroi qui la délimite est plus fine que celle des végétaux. C'est une membrane souple. Les végétaux aussi ont cette membrane, mais elle est doublée par une membrane bien plus épaisse qui confère aux tiges leur rigidité et au bois sa consistance.
Les biologistes ont effectué des milliers d'observations. Ils ont constaté que tous les tissus végétaux et animaux connus sont constitués de cellules. Les cellules sont les briques élémentaires de la construction des organismes vivants.
Les cellules sont faites d'une membrane, sorte de poche-réservoir, remplie d'une substance souple un peu visqueuse (le cytoplasme). Elles se présentent sous des aspects extrêmement variés, aussi bien en taille qu'en structure interne. La taille varie de 1 à 100 µm (0,1 mm) avec une moyenne de 20 µm. Les façons dont elles s'assemblent pour former un tissu sont également très diverses et très inventives.
Les cellules sont pourvues d'un noyau, mises à part celles de certains organismes primaires microscopiques tels que les bactéries. Le noyau est contenu lui-aussi dans une membrane souple.
La forme des cellules isolées n'est pas fixe. Pendant l'observation, on les voit bouger et se déformer. Elles sont plastiques et fluctuantes, car elles sont vivantes.
A l'intérieur, elles sont parcourues de courants de matière fluide. Des études biochimiques ont montré que ces courants transportent des substances qui, tout comme notre sang, assurent les échanges de matière à l'intérieur de la cellule, en particulier avec le noyau. La membrane du noyau est perméable et laisse passer ces substances de façon sélective. C'est également le cas de la membrane extérieure, afin d'assurer les échanges entre cellules, entre tissus, entre organes.
Si vous souhaitez en savoir plus sur les cellules et les observer de façon vivante et expérimentale, je vous recommande l'excellent site La biologie amusante.
C'est dans le noyau qu'on a découvert, analysé, identifié la substance qu'on a nommé ADN. Au début, le but des biologistes n'était pas de rechercher cette substance dont ils ignoraient l'existence. Ils voulaient observer et décrire comment évoluaient les cellules au cours du temps. Ils les voyaient grandir et se diviser en deux autres cellules, et voulaient comprendre par quel mécanisme biologique cela se produisait.
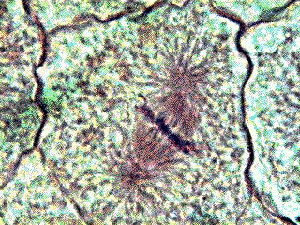
C'est par le procédé de coloration mentionné ci-dessus qu'ils ont vu apparaitre les chromosomes juste avant la phase de séparation de la cellule en deux cellules-filles. Le mot chromosome signifie d'ailleurs que c'est une figure colorée, sans préfigurer de sa fonction ni de sa composition. A ce stade de vie de la cellule, cette figure a l'apparence de 2 faisceaux en éventail ou en étoile (fig.7).
 |
 |
 |
| Fig.7- Phase de division de la cellule en 2 cellules-filles. La membrane du noyau n'est plus visible. Microscope optique. Coloration |
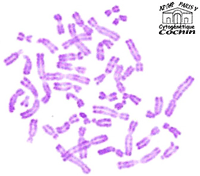
Fig.8- Chromosomes dans le noyau pendant la division de la cellule humaine. Microscopie optique coloration au giemsa Merci au Pr J.M. Dupont, Faculté de Médecine, Cochin, Paris |
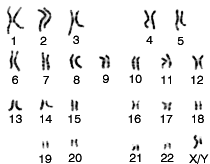
Fig.9- Caryotype humain montrant les 23 paires de chromosomes. La 23e détermine le genre
masculin (XY, ici) ou féminin (XX). Merci à Wikipedia |
La figure évolue rapidement et les chromosomes deviennent distincts les uns des autres pendant un bref instant. C'est à ce moment qu'on peut les observer le plus commodément et les photographier au microscope optique. Cela demande certains traitements chimiques. On fixe la cellule dans son évolution, on la gonfle, on la colore. La figure 8 présente la photographie des chromosomes d'un être humain et plus précisément d'un homme. Il est possible de découper l'image (cela se fait par ordinateur) pour isoler chacun des chromosomes et les disposer les uns à côté des autres. Puis on les dénombre et on observe leur forme. Enfin on les classe par ordre de grandeur décroissante. La figure obtenue s'appelle le caryogramme de la cellule (fig.9). Or toutes les cellules d'un même individu présentent ce même caryogramme. Le caryogramme est donc typique d'un individu et pour cette raison on le nomme aussi un caryotype.
Dans le caryotype des humains, on remarque tout d'abord qu'il y a 2 exemplaires identiques de chacun des chromosomes, à une exception près. On peut donc les classer par paires. Il y a 22 paires de chromosomes identiques et une 23e paire qui est composée de 2 chromosomes qui différent pour l'homme et pour la femme. Chez la femme, les 2 chromosomes de la 23e paire sont également identiques. On les a nommé X. Chez l'homme l'un est ce chromosome X et l'autre un chromosome bien plus petit nommé Y. Chacune des paires est repérée par son numéro d'ordre.
En réalité, les chromosomes d'une même paire ne sont pas tout à fait identiques, mais seulement homologues. Dans chacune des paires, l'un des chromosomes est hérité du père et l'autre de la mère, au moment de la fécondation et de la formation des premières cellules de l'embryon. Mais cette différence ne peut être distinguée qu'en analysant leur composition moléculaire en ADN et protéines, et en décrivant l'ADN à l'échelle moléculaire, comme nous allons le faire.
1869: le biologiste suisse Friedrich Miescher (1844 - 1895) isole une substance dans le pus de bandages chirurgicaux usagés. Elle est riche en phosphore. Il la nomme nucléine.
1878: le biochimiste allemand Albrecht Kossel (1853 - 1927) isole les composants de la nucléine: les acides nucléiques, puis identifie les cinq bases nucléiques (A, C, G, T, U).
1919: le biologiste américain Phoebus Levene (1869 - 1940) identifie les constituants des nucléotides: une base, un sucre et un groupe phosphate. Il suggère que l'ADN consiste en une chaine de nucléotides reliés par leurs groupes phosphate.
À ce stade, on a découvert la molécule d'ADN et sa structure chimique, mais rien n'indique qu'elle joue un rôle dans l'hérédité.
1944: Expérience de Avery, MacLeod et McCarty prouvant que le code génétique est inscrit dans l'ADN (voir plus loin l'annexe Démonstrations expérimentales de la localisation du code génétique dans l'ADN)
1946: Le biochimiste belge Jean Brachet (1909 - 1988) démontre que l'ADN est un constituant des chromosomes.
Sources: Acide désoxyribonucléique dans Wikipédia; La première découverte de l'ADN, Ralf Dahm, 30 novembre 1999, Pour la Science n° 371; Discovering DNA: Friedrich Miescher and the early years of nucleic acid research, Ralf Dahm, septembre 2007, Human Genetics, DOI 10.1007/s00439-007-0433-0; Avery– MacLeod– McCarty experiment dans wikipedia
À ce stade d'observation, rien ne nous indique que ce sont les chromosomes qui sont les porteurs des informations héréditaires. Nous devons d'abord découvrir la molécule d'ADN. Puis en examinant les mécanismes de l'hérédité, nous pourrons déterminer que l'ADN en est le transmetteur.
Toute matière est faite d'un assemblage de molécules et les chromosomes ne font pas exception. L'analyse chimique d'un chromosome révèle qu'il est constitué d'ADN et de protéines.
Ce qui est remarquable, c'est que l'ADN du chromosome est constitué d'une seule molécule, donc cette molécule est énorme. Elle a la forme d'un filament souple comme une ficelle qui prend différentes dispositions selon les moments de la vie cellulaire. Il peut se replier en boule, ou s'allonger en partie.
Le filament d'ADN le plus long du corps humain est celui du chromosome n°1 qui, une fois déroulé, mesure environ 8 cm. C'est énorme quand on sait que les molécules synthétiques les plus longues des matières plastiques mesurent à peine 1 centième de millimètre (voir mon article Molécules des polymères). Le noyau de chaque cellule humaine contient 46 chromosomes, donc 46 molécules d'ADN. Si on pouvait les dérouler et les mettre bout à bout, elles totaliseraient une longueur de plus de 1 mètre.
Dans certaines circonstances, il est possible, après un traitement spécifique, de photographier des filaments d'ADN par microscopie électronique (fig.10). Leur diamètre est estimé à 2 nanomètres (millionièmes de millimètre).
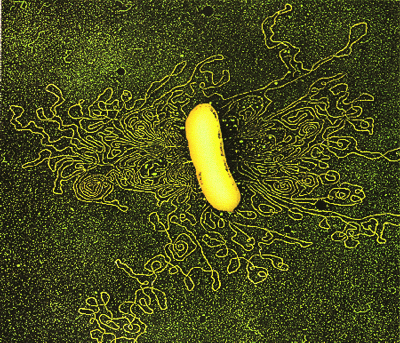 |
| Fig.10- Par un traitement spécifique, le filament d'ADN d'une bactérie (le haricot central d'environ 1 µm de long) s'est répandu tout autour d'elle (le fil jaune) Microscopie électronique en transmission. Couleur jaune artificielle ajoutée par informatique |
Diverses techniques d'analyse chimiques et physiques ont permis de dresser les caractéristiques de la molécule d'ADN. Elle est semblable à un fil sur lequel on aurait enfilé des perles. L'image du fil doit être corrigée en précisant qu'il est composé à la manière d'une chaine, un assemblage de chainons identiques. Les chainons sont un petit motif moléculaire appelé désoxyribose (fig.11). Notons en passant que la petite molécule de ribose dont est dérivé le désoxyribose est nommée ainsi parce qu'elle a été étudiée au Rockfeller Institute of Biochemistry (RIB).
Sur cette chaine, sont fixées les perles. Non, elles ne coulissent pas. Sur chacun des groupements désoxyriboses est fixée l'une de ces perles, nommée en chimie une base azotée. Les groupements ont le choix entre 4 catégories de perles qui différent par leur composition chimique. Autrement dit, elles ne sont pas composées avec les mêmes atomes. Deux des catégories sont plus grosses. Ce sont les perles A (adénine) et G (guanine). Les deux autres sont plus petites: T (thymine) et C (cytosine).
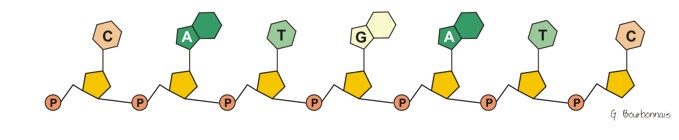 |
| Fig.11- Schéma de la molécule d'ADN. Elle est composée d'une chaine centrale, faite de l'assemblage linéaire de motifs
identiques (les pentagones oranges articulés par le groupement P ),
sur
laquelle sont fixés des groupements C, A, T et G Merci à G. Bourbonnais |
Les molécules qui sont composées d'une chaine d'un grand nombre de motifs semblables sont appelées des polymères (poly = plusieurs; mère = le motif qui génère la molécule).
Il existe des polymères naturels tels que l'ADN, les protéines ou la cellulose, et des polymères synthétiques tels que les matières plastiques, les peintures ou les gels (voir mon article Les polymères).
L'ADN est un polymère de nucléotides.
D'où vient ce nom d'ADN? Il a été forgé selon la nomenclature usuelle chez les chimistes. ADN est l'abréviation de Acide Désoxyribo-Nucléique. Il fait référence à sa composition chimique, mais pas du tout à sa fonction génétique. Le désoxyribo- renvoie au désoxyribose des chainons.
Son côté acide ne fait pas référence à son gout, mais aux atomes de phosphore P et d'oxygène O qui sont accrochés en appendice aux chainons (sur la fig.11, l'ensemble des atomes P et O est représenté par le symbole P qui signifie phosphate). Ce groupement acide intervient au moment où la molécule est construite (synthétisée) dans le noyau. Les chainons s'ajoutent un à un à l'extrémité de droite (sur la figure 11) et les groupements P servent de liens entre les chainons.
Enfin l'adjectif nucléique indique que cette molécule est extraite du noyau (nucleus) de la cellule. En fait, par la suite, on a aussi trouvé de l'ADN dans certaines petites inclusions de la cellule situées en-dehors du noyau, les mitochondries.
Les chimistes utilisent également le terme nucléotide. Un nucléotide désigne l'ensemble de la base azotée (la perle) et du chainon à laquelle elle est accrochée (un désoxyribose et un groupement P - voir fig.11).
Les molécules d'ADN ne sont pas toutes identiques. Il n'y a pas qu'une seule molécule d'ADN possible comme il y a une seule molécule de soude ou d'ammoniaque. Même si toutes les molécules d'ADN sont construites sur le même schéma de structure dont on vient de prendre connaissance, elles différent entre elles par deux aspects. D'abord, par le nombre de chainons. La longueur de la molécule d'ADN peut être très variable. Elle est différente d'une paire de chromosomes à l'autre, et c'est pourquoi les chromosomes ont des tailles différentes. Le plus long (chromosome 1) comporte 263 millions de chainons. Enroulés sur eux-mêmes dans les chromosomes, les ADN longs sont plus volumineux que les ADN plus courts.
D'autre part, l'ordre de succession des bases azotées, A, C, G, T le long de la chaine est lui-aussi extrêmement variable. Il n'y a pas de régularité dans leur arrangement. Elles semblent se succéder au hasard. Toutefois, ce n'est qu'apparence, car l'ordre de leur disposition répond à un sens. C'est sur cet ordre variable que repose le code génétique qui est inscrit dans l'ADN comme on va le voir.
Nous venons de décrire la nature et la succession des chainons. Reste à savoir comment la chaine est disposée globalement. Allongée, en pelote ou autrement? C'est ce qu'on nomme sa configuration. Quelle figure adopte-t-elle? La détermination par les scientifiques de la composition de la chaine telle qu'on vient de l'exposer a été effectuée morceau par morceau sur des fragments d'ADN et le schéma de la fig.11 en présente les résultats comme si la molécule était étirée. En réalité, ce n'est pas le cas.
Comme on l'a mentionné, extérieurement, le filament d'ADN ressemble à un tube souple et flexible d'un diamètre de 2 nanomètres. Mais quelle est la disposition de la molécule dans ce tube? Avez-vous déjà vu ces guirlandes lumineuses de Noël, constituées de petites ampoules reliées par un fil électrique, fourrées dans un tube en plastique transparent? Imaginez que le fil électrique, au lieu d'être droit le long de l'axe du tube, s'enroule en spirale à l'intérieur. Maintenant imaginez qu'il y a deux fils enroulés en spirale avec un léger décalage. Et bien, nous avons une image approchée de la figure de la molécule. Précisons.
D'abord, le schéma de la figure 11 ne montre que la moitié de la molécule. Le diamètre du tube est suffisant pour loger deux brins parallèles. Ces deux brins sont comme les montants d'une échelle. Les barreaux sont les bases azotées qui s'accouplent. Les brins se trouvant face à face, il est facile pour chaque base de s'agripper à la base qui se trouve en face sur l'autre brin.
Enfin, ces brins sont enroulés en hélice, c'est-à-dire en spirale le long du tube. Bien sûr, il n'y a pas de tube qui enveloppe les brins comme dans la guirlande. Le tube est l'image extérieure que dessinent les deux brins (fig.12). Qu'est-ce qu'une hélice? Un exemple concret d'hélice que vous avez peut-être touchée, c'est la reliure des cahiers dits spiralés, ou les ressorts à boudin (pour en savoir plus sur les spirales et les hélices, voir mon article sur ce sujet). Imaginez que vous prenez 2 ressorts de ce type et que vous les emboitez l'un dans l'autre. C'est exactement la structure que prend l'ADN. C'est la double hélice.
En résumé, imaginez une petite échelle souple déformable que vous prenez aux deux extrémités et vous la tordez comme un linge qu'on essore. Vous obtenez la forme en double hélice. Oui, mais on peut la tordre dans un sens ou dans l'autre. L'ADN est une hélice qui tourne sur la droite. Ça veut dire que si c'était un tire-bouchon, vous tournez à droite pour le faire avancer, comme le tire-bouchon normal. Idem avec une vis ou un boulon. L'ensemble de ces informations est représenté sur la figure 12.
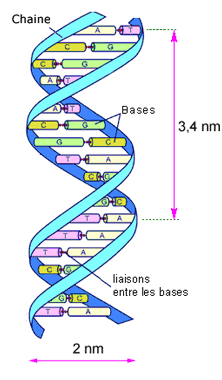 |
 |
 |
| Fig.12- Forme de la molécule d'ADN Les 2 brins sont enroulés en hélice autour d'un axe commun, et réunis par des liaisons horizontales entre bases azotées |
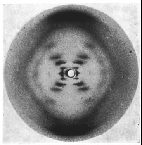
Fig.13- Diagramme de diffraction des rayons X par un échantillon d'ADN Reproduit avec l'aimable autorisation de Macmillan Publishers Ltd: Nature 171, 740 © Copyright 1953 |
|
Revenons aux barreaux de l'échelle. Les bases azotées ne s'accouplent pas avec n'importe qui. On rencontre seulement deux types d'associations: les bases A+T et les bases C+G. Il y a une stricte complémentarité entre les deux brins.
Historiquement, c'est le physicien et biologiste moléculaire britannique William Astbury (1898 - 1961) qui a réalisé en 1937 le premier diagramme de diffraction de l'ADN par cristallographie aux rayons X. Il a montré que l'ADN possède une structure ordonnée.
En 1953, la physico-chimiste britannique Rosalind Franklin (1920 - 1958) et ses collègues ont obtenu des diagrammes X montrant qu'il s'agit d'une double hélice.
Peut-être est-il utile de préciser la façon dont elle est déterminée par la diffraction des rayons X (fig.13). Non, la détermination n'est pas possible sur un seul filament d'ADN tel que le montre la photographie en microscopie électronique (fig.10). Il faut que l'échantillon d'ADN analysé ait une volume suffisant, environ un dixième de millimètre minimum. C'est petit pour nous, mais très gros à l'échelle moléculaire.
C'est pourquoi le biochimiste suisse Rudolf Signer (1903 - 1990) a extrait de l'ADN d'une cellule (de thymus de veau) avec grand soin et l'a arrangé en un empilement serré presque cristallin (exactement une structure de fibre). Techniquement, c'est un exploit.
Rosalind Franklin, Raymond Gosling (physicien britannique, 1926 - 2015), et Maurice Wilkins (biologiste néozélandais, 1916 - 2004) en ont obtenu le diagramme X et l'ont interprété partiellement. James Watson (généticien états-unien, né en 1928) et Francis Crick (biologiste britannique, 1916 - 2004) l'ont interprété complètement (tous les deux prix Nobel en 1962 avec Wilkins).
Reste à savoir si cet ADN extrait a la même configuration que lorsqu'il est dans la cellule.
Sources: Rosalind Franklin
dans wikipédia; Short and Simple (ish)
Guide to X-ray Diffraction, in
DNA and Social Responsibility: Cataloguing the personal papers of Maurice Wilkins
Comme dans toute association, les liens de couple sont plus ou moins solides. La force de liaison entre bases azotées est relativement faible de sorte que les couples peuvent à volonté se faire et se défaire selon les circonstances. Si ça chauffe, ou si le couple est soumis à des tiraillements provenant du milieu ambiant, les liens peuvent facilement se défaire.
Quelle est donc la nature physique de cette force de liaison? C'est une affinité d'ordre électrique. Car les molécules sont faites d'atomes qui eux-mêmes sont constitués de grains d'électricité. La molécule est un monde d'électricité qui circule et oscille. Des échanges électriques ont lieu entre molécules, révélant attirances et répulsions plus ou moins marquées. Cet aspect est développé dans la cinquième partie de cette série, L'ADN électrique.
La popularisation de l'image de l'ADN en double hélice a l'inconvénient de la présenter comme une structure immuable. Mais non, l'ADN a une vie. L'ADN bouge, se transforme selon ses tâches quotidiennes, autrement dit selon les phases de la vie cellulaire. Les brins peuvent se séparer partiellement, sur une petite longueur, ou totalement. [Pause pour un couplet sémantique: les biologistes appellent cette séparation une dénaturation. La séparation ne serai-elle donc pas naturelle? Bien sûr que si. Exemple parmi bien d'autres de la négligence avec laquelle les mots sont choisis généralement en anglais par les chercheurs, repris en chœur par ses collègues, puis traduits en français.]
Par d'autres types d'investigation, on en arrive actuellement à la conclusion que la forme en double hélice est la plus courante dans la cellule, mais qu'il en existe d'autres variantes. Des doubles hélices moins ou plus serrées. Des formes en croix, en épingle à cheveux. Des formes où 3 brins s'assemblent sur une partie. Et une forme à 4 brins accolés. (Voir en annexe des précisions ainsi que des compléments sur le nombre d'or qui apparait comme rapport entre certaines mesures)
Comment en est-on arrivé à conclure que le code génétique est inscrit dans l'ADN? Par une autre série d'investigations qui portent sur l'hérédité et son fonctionnement. Qu'est-ce que l'hérédité?
L'idée et les preuves expérimentales que le code génétique est situé dans l'ADN est le résultat des recherches effectuées par un ensemble de scientifiques depuis la fin du 19e siècle, conjuguées avec la mise au point de techniques sophistiquées d'analyse, ainsi que l'apparition des manipulations génétiques. Ce n'est que peu à peu que cette connaissance a obtenu le consensus de la communauté scientifique, car les chercheurs scientifiques n'échappent pas aux sentiments humains qui se manifestent dans toutes les activités humaines: admiration, engouement, besoin de reconnaissance, controverse, incrédulité, dogmatisme, jalousie, orgueil...
Les observations ont été menées parfois sur des cellules humaines, mais le plus souvent sur des cellules végétales ou animales choisies pour leurs avantages expérimentaux. Par exemple, les mouches se reproduisent très vite et on peut observer leur descendance quelques jours ou quelques semaines après seulement. Les vers étudiés ont peu de chromosomes, ce qui facilite la compréhension de leurs transformations, etc. On observe les aspects physiques (couleur des yeux, forme des ailes des mouches, couleur du pelage de la souris) ou encore des anomalies héréditaires du fonctionnement métabolique du corps.
Dans les années 1860, le botaniste austro-hongrois Gregor Mendel (1822 - 1884) observe les caractères d'une variété de pois et la façon dont ils se transmettent au cours de croisements entre deux espèces différentes. Un croisement consiste à prendre du pollen d'une variété et le déposer sur le pistil d'une autre pour le féconder. Il n'y a pas manipulation génétique directe, mais une accélération manuelle de ce que fait habituellement la nature.
Mendel examine des caractères bien visibles tels que la couleur de la graine. Il découvre que la couleur de la descendance est soit verte soit jaune, mais pas de couleur intermédiaire. De l'étude de la statistique d'apparition des couleurs dans la descendance, il déduit que chaque caractère est forcément transmis par des supports concrets distincts et indépendants, les facteurs, qu'on appellera plus tard les gènes. Par exemple, il y a un gène pour la couleur verte et un autre pour la couleur jaune.
Dans les années 1900 - 1930, d'autres chercheurs (Sutton, Morgan) montrent que les gènes sont localisés dans les chromosomes, par une observation fine de la forme de ces chromosomes au cours de la division de la cellule en deux cellules filles, en particulier en mettant en relation l'hérédité propre à chacun des sexes et le rôle des chromosomes sexuels X et Y.
En 1928, le bactériologue anglais Frederick Griffith (1879 - 1941) effectue une expérience célèbre. Il démontre que des bactéries vivantes (pneumocoques) non virulentes pour la souris, mises en contact avec des bactéries virulentes tuées par la chaleur pouvaient être transformées en bactéries virulentes. Il en déduit l'existence d'un "principe transformant".
L'expérience fut reprise en 1944 par 3 américains, Oswald Avery (chirurgien canadien, 877 - 1955), Colin MacLeod (généticien canadien, 1909 - 1972), and Maclyn McCarty (généticien états-unien, 1911 - 2005). Elle permit de montrer que l'agent virulent est codé par un gène. Ils ont été capables de transmettre ce gène de la variété virulente à l'autre non virulente, et de la rendre virulente, en prenant l'ADN aux bactéries virulentes pour l'ajouter à la population non virulente.
En 1952, le rôle de l'ADN dans l'hérédité fut confirmé par les expériences du généticien états-unien Alfred Hershey (1908 - 1997, prix Nobel 1969) et de la généticienne états-unienne Martha Chase (1927 - 2003) qui démontrèrent que le matériel génétique d'un virus (le phage T2) est constitué d'ADN.
C'est donc bien l'ADN qui porte les gènes.
Sources: Dans wikipedia: Acide désoxyribonucléique; Avery MacLeod McCarty experiment; Expériences de Hershey et Chase
Il est d'observation courante que certaines caractéristiques de notre corps sont héritées de nos parents. Nous ressemblons à notre père ou notre mère, à notre grand-mère ou notre grand-père. Ces ressemblances portent sur des caractères physiques. La forme du nez ou de la bouche, la couleur des yeux, celle des cheveux, la taille, etc. Quelquefois, c'est une tare physique qui est transmise dans une famille par-delà les générations, ou une maladie. Comment cette transmission est-elle possible?
Il faut admettre que notre programme de développement physique, notre code génétique, inclue certaines informations qui proviennent de nos parents. Biologiquement, c'est au cours de la fécondation que le nouvel être hérite des programmes de ses parents. La fécondation consiste à créer la première cellule du nouvel être à partir d'une cellule du père (le spermatozoïde) et une cellule de la mère (l'ovule). C'est au moment de la fécondation que se constitue le code génétique du nouvel être, à partir de chromosomes provenant du père et d'autres provenant de la mère. Puis la cellule initiale se multiplie jusqu'à devenir un organisme complet dans lequel chacune des cellules porte le même code génétique.
Les conclusions des recherches expérimentales des biologistes ont conduit à proposer le schéma suivant sur la nature et la structure des gènes.
Un gène est une portion de chromosome, ou plus exactement une portion de l'ADN qui le constitue, une portion qui porte une instruction déterminant un caractère physique de l'organisme vivant, végétal, animal ou humain. Exemple: chez l'humain, l'instruction concernant la couleur des yeux est inscrite à un emplacement précis du chromosome 15.
Or pour certaines personnes, le gène de la couleur des yeux donne l'instruction pour la couleur bleue et pour d'autres pour la couleur brune, par exemple. Cela signifie qu'elles n'ont pas le même gène. Mais alors comment le corps sait-il que dans les deux cas, c'est le gène qui code la couleur des yeux? C'est l'emplacement du gène qui détermine quelle en est la fonction. Le gène possède un marqueur de début qui indique que là commence l'instruction "Couleur des yeux" et un marqueur de fin. Plus loin, nous verrons quel est le langage utilisé pour coder ces instructions.
Ainsi, on peut se représenter un chromosome comme une suite d'emplacements que nous assimilerons à des cadres d'affichage. Comme si dans le couloir d'une société, toutes les portes de bureau sont équipées de la même plaque où est inscrit le numéro du bureau. La fonction de la plaque est la même, afficher un numéro, mais le numéro lui-même, l'information, diffère d'une porte à l'autre. En outre, en-dessous de cette plaque, figurent deux autres, l'une donnant le nom de la personne, l'autre sa spécialité (secrétaire, etc). Les plaques sont disposées de la même façon sur chacune des portes, aux mêmes emplacements.
Dans les chromosomes, c'est la même chose, à chaque emplacement de la chaine d'ADN est affectée une fonction, par exemple la couleur des yeux. Ces emplacements bien précis sur les chromosomes sont nommés loci (un locus) par les biologistes.
Pour quelle raison les chromosomes existent-ils par paires? (Attention, ne pas confondre avec le fait que la molécule d'ADN d'un chromosome a deux brins). Pourquoi l'organisme juge-t-il bon d'avoir des paires de chromosomes identiques?
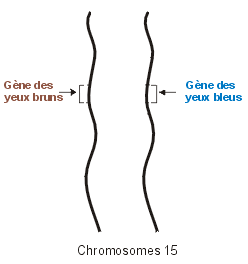
Fig.14- Dans les paires de chromosomes homologues, l'un vient du père, l'autre de la mère. Certains gènes peuvent être
différents de l'un à l'autre.
Merci à G.
Bourbonnais
Identiques au moins en ce qui concerne leur forme apparente, car au niveau moléculaire, il se révèle qu'ils ne sont pas complètement identiques. Dans des chromosomes homologues, les emplacements ou loci sont identiques, les instructions données, les gènes, le sont pour une grande partie, mais pas tous. Car l'un des chromosomes vient du père et l'autre vient de la mère. C'est au cours de la création de la première cellule d'un être, au cours de la fécondation d'un ovule et d'un spermatozoïde, que se produit l'appariement des deux chromosomes.
Les cellules sexuelles, ovules et spermatozoïdes, sont des cellules différentes des autres cellules parce qu'elles ne possèdent que 23 chromosomes. Mises à part ces cellules sexuelles, toutes les cellules d'un être humain possèdent le même ensemble de 23 paires de chromosomes et les mêmes gènes. Or dans les organes de production des cellules sexuelles (ovaires, testicules), ces cellules se divisent en deux cellules filles d'une façon spéciale. Les paires de chromosomes homologues se dissocient en deux ensembles de 23 chromosomes qui sont affectés à chacune des cellules filles sexuelles.
Les cellules sexuelles d'un même individu ne sont donc pas toutes identiques par leurs gènes puisque ceux-ci peuvent provenir soit de l'un soit de l'autre chromosome homologue. Bien plus surprenant, il se produit même à ce moment un contact et des échanges de gènes entre les deux chromosomes avant la séparation complète.
Au cours de la fécondation, c'est le processus inverse. Deux cellules sexuelles de 23 chromosomes (l'ovule et le spermatozoïde) fusionnent pour donner une cellule nouvelle de 23 paires de chromosomes. Un chromosome de l'ovule s'associe avec le chromosome homologue du spermatozoïde. C'est la cellule initiale de l'être.
Si l'on compare les chromosomes homologues, on constate que la plupart des gènes de l'un sont les mêmes que ceux de l'autre. Ce sont eux qui déterminent les caractéristiques communes aux êtres humains. Ce sont les gènes de l'espèce humaine, et ceux de la race du corps que nous habitons.
Mais il existe aussi de subtiles différences entre les gènes des chromosomes homologues. Par exemple, sur la paire 15 (fig.14), l'un
des chromosomes peut porter le gène codant pour des yeux bleus alors que l'autre porte, au même endroit, un gène codant pour des yeux bruns. Les deux
gènes codent pour une même fonction (la couleur des yeux), mais ne codent pas pour la même couleur. Finalement, quelle est la couleur des yeux de cette
personne? Il apparait que l'un des gènes a une fonction dominante par rapport à l'autre qui est qualifié de récessif.
Comment? Mystère! Peut-être ce mystère deviendra-t-il moins mystérieux lorsque nous évoquerons l'architecture de l'ADN et la fonction des zones entre
les gènes. (voir Architecture de l'ADN)
À ce stade de l'article, nous savons que les gènes contenus dans l'ADN des chromosomes codent pour un caractère physique. Comment est-ce possible? Comment un bout de molécule d'ADN peut-il déclencher une machinerie qui va fabriquer les cellules de l'iris de l'œil d'une certaine couleur, par exemple? La réponse se trouve dans le rôle que jouent certaines grosses molécules du corps, les protéines.
Peut-être connaissez-vous les protéines dans l'alimentation? Les aliments que l'on classe parmi les protides sont les aliments riches en protéines: protéines d'origine animale telles que œufs, fromages, chair animale, mais aussi protéines issues de végétaux telles que les légumineuses (lentilles, pois, soja, haricots) ou les noix diverses (noix, noisettes, amandes).
Les protéines ont d'abord été reconnues par l'importance de certaines substances comme l'hémoglobine dans le fonctionnement du corps. Protéine signifie d'ailleurs d'importance primordiale. L'hémoglobine se trouve dans les globules rouges du sang. Elle se recharge en oxygène dans les poumons au moment de l'inspiration et elle va le livrer dans tout le corps, toutes les cellules. C'est la démonstration du rôle essentiel d'une molécule dans le bon fonctionnement de l'organisme entier.
Peu à peu, les scientifiques ont découvert que de nombreuses fonctions dans les cellules sont assurées par des protéines. Certaines sont les matériaux de construction de la cellule et du tissu qui les entoure. Parmi leurs nombreux rôles, les hormones et les enzymes sont des éléments essentiels du métabolisme humain. Les enzymes sont les facteurs qui régulent tous les processus de vie en intervenant dans les réactions chimiques d'absorption, digestion, assimilation, et croissance au niveau des cellules.
Bien que les rôles et les dimensions des protéines soient très divers, elles présentent une structure chimique commune. Comme l'ADN, elles sont constituées d'un collier de perles. Les types de perles sont au nombre de 20 (au lieu de 4 pour l'ADN), et ce ne sont pas des bases azotées, mais des groupements que l'on appelle des acides aminés. En langage chimique, les protéines sont des polymères constitués de l'assemblage de nombreux acides aminés pris parmi 20 types différents.
Où ces informations nous mènent-elles? La vie des cellules est régulée par des protéines... Les caractères physiques sont élaborés par les protéines comme ouvrières spécialisées... Donc les gènes déterminent les caractères physiques parce qu'ils commandent la fabrication des protéines.
En définitive, un gène est une portion de l'ADN qui porte le code de fabrication d'une protéine.
Si nous brossons une vue d'ensemble des gènes humains, avec leur fonction, et leur localisation dans les chromosomes, nous aboutissons à une carte nommée le génotype. Le génotype est constitué de l'ensemble des gènes qui ont été repérés comme codant pour une protéine, qui a été identifiée (fig.15).

Fig.15- Carte génique du chromosome 15. Chaque bande colorée représente un gène. En face est inscrite sa fonction, qui est la détermination d'un trait physique ou d'un désordre organique.
(Extrait du site Human Genome Project où l'on peut trouver la carte de tous les chromosomes)
Le séquençage complet du génome humain a été terminé en 2004, soit il y a quelques années seulement. Compte tenu de la complexité de l'organisme humain et du nombre de types de protéines nécessaires à son bon fonctionnement, les chercheurs s'attendaient à un nombre très important de gènes. La surprise a été de taille quand ils ont appris qu'il y en avait en fait très peu. On en a dénombré environ 25'000 répartis dans les 23 paires de chromosomes. Les protéines qui leur correspondent contrôlent d'une part certains caractères physiques, et d'autre part certains types de maladies héréditaires. Le petit nombre de gènes a appelé l'attention sur le rôle des autres parties, non-codantes, de l'ADN (voir Architecture de l'ADN).
Il est surprenant que les biologistes aient exprimé le génotype par les déficiences organiques. On se serait attendu à ce qu'une protéine code pour un potentiel, une fonction d'épanouissement ou d'intégrité corporelle. C'est comme si on définissait l’œil par la cécité et le foie par la cirrhose. Les biologistes préfèrent se centrer sur les défauts des protéines et les manques de l'organisme. C'est révélateur d'une mentalité!
Puisqu'un gène est une portion de l'ADN et que l'ADN est un enchainement de bases azotées (fig.11), un gène est une courte séquence de bases azotées. Cette séquence comporte un début et une fin. Concrètement les indicateurs de début et de fin de gène sont une séquence particulière de 3 bases azotées.
Au total, la séquence d'un gène comprend ces indicateurs, des bases qui codent pour une protéine, et aussi d'autres suites de bases non-codantes, qui sont intercalées dans les régions codantes du gène. Ces séquences de bases non-codantes à l'intérieur des gènes sont appelées introns. Les régions codantes sont nommées exons.
Lorsqu'on examine les emplacements de tous les gènes d'un chromosome, on constate qu'ils n'occupent qu'une faible partie de l'ADN. De longues régions non-codantes séparent les gènes. Au total, on a des régions non-codantes à l'intérieur des gènes (introns) et entre les gènes. Finalement, les régions codantes de l'ADN sont en faible proportion - seulement 1,3% chez les humains - ce qui laisse 98,7% de régions non-codantes.
Pendant des années, ces régions non-codantes ont été taxées d'inutiles et même de déchet ou de poubelle (junk), d'après l'expression d'un chercheur, S.
Ohno en 1972 (So Much, Junk DNA in our Genome). Depuis
quelques années, il est devenu clair qu'elles ont des fonctions importantes de régulation (voir partie 3: Architecture
de l'ADN).
Le génome, c'est l'ensemble de toutes les séquences de bases azotées de l'ADN de la totalité des chromosomes (le caryotype, fig.9), qu'elles soient codantes ou non. Le génotype est la partie du génome qui est codante, constituée de l'ensemble des exons.
La détermination du rôle des protéines et de leur codage par les gènes a demandé un certain temps chez les scientifiques. Elle a profité de la convergence de nombreuses techniques modernes d'analyse chimiques (marquage par des molécules radioactives, découpage de l'ADN par des enzymes, ..) et physiques (détermination de la structure des protéines par la diffraction des rayons X).
Morgan parvient à localiser les gènes de la mouche sur les chromosomes en observant leurs recombinaisons au cours de la fécondation et leur manifestation dans la descendance. Muller découvre le moyen de provoquer un fort taux de mutation (modification) des gènes en irradiant les mouches avec des rayons X.
Beadle et Tatum montrent que la production d'enzymes (qui sont des protéines) dans des cellules de champignons peut être rendue déficiente par irradiation et que la déficience est transmise génétiquement. Ils montrent qu'à un gène correspond un enzyme.
Dans les cellules, on trouve des molécules d'ARN, sorte de fragments courts d'ADN. Cet ARN joue le rôle d'un moule en creux du gène. Il reproduit le gène par complémentarité des bases: C est reproduit en G par exemple. A est reproduit, non en T, mais en une variante spécifique à l'ARN appelée uracile (U). Ainsi le codon CGA de l'alanine est moulé en GCU. Les introns sont dans un premier temps transcrits, puis rapidement évacués. Puis cet ARN se déplace et va créer la protéine dans son atelier (d'où son qualificatif de messager). [À ce sujet, voir en annexe Les vaccins à ARN]
En mettant des acides aminés en présence d'une molécule d'ARN, Khorana obtient des protéines dont la séquence en acides aminés est le reflet de la séquence des codons de l'ARN. En synthétisant d'autres ARN messagers, et en utilisant des molécules marquées, on a pu déchiffrer tous les gènes.
Dans la compréhension du code génétique, il nous reste à décrypter comment un gène se fait entendre. Par quel langage exprime-t-il l'ordre de fabriquer une protéine précise?
Souvenons-nous que les protéines sont des chaines constituées de l'assemblage de 20 types d'acides aminés. Le gène déroule la liste ordonnée des acides aminés qui doivent être convoqués et assemblés pour construire la protéine correspondante. Après l'indicateur de début de gène, vient l'instruction de convoquer le premier acide aminé, puis le deuxième qui sera accroché au premier et ainsi de suite, jusqu'à l'indicateur de fin.
La question est donc maintenant la suivante. Par quel langage le gène exprime-t-il l'ordre de convoquer un acide aminé précis? Il le fait au moyen d'un code.
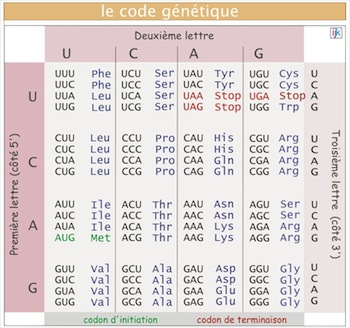
Chaque acide aminé est représenté (nommé) par 3 lettres prises parmi un ensemble de 4 lettres. Ces lettres, ce sont les bases azotées, A, C, G et T. Autrement dit un acide aminé est convoqué par la succession dans un ordre précis de 3 bases sur la chaine d'ADN. L'ensemble de ces 3 bases est appelé un codon.
Par exemple, la séquence GAC commande l'appel de la leucine. Le codon ACC commande l'appel du tryptophane et le codon CGA celui de l'alanine.
Or l'ADN étant constitué de deux brins complémentaires, un codon a son complément en miroir. Lequel des deux est opérant? On a pu établir que l'information pour un codon donné n'est portée que par une seule des deux chaines. Le miroir sur le second brin joue le rôle de stabilisateur. Porter des codons n'est pas le privilège d'une seule chaine. On trouve des codons sur les deux.
Concrètement, le gène est transcrit en une molécule d'ARN de même longueur, puis les séquences correspondant aux introns sont éliminés, et c'est cette molécule raccourcie d'ARN qui va transporter le code (voir encadré). Le code de l'ARN est complémentaire du code ADN. Ainsi, le code ADN de la leucine qui est GAC, est transcrit en CUG dans l'ARN. Généralement, les auteurs fournissent des tables du code de l'ARN.
Chacun des 20 acides aminés est affecté d'un code, mais ce code n'est pas obligatoirement unique. Certains acides aminés ont reçu plusieurs codes qui sont équivalents. Par exemple, l'alanine est codée non seulement par GCU, mais alternativement par GCC, GCA ou GCC. Le nombre de codons équivalents peut varier entre 1 et 6 selon les acides aminés.
Puisqu'une protéine est constituée de l'enchainement de plusieurs acides aminés, le gène qui code pour cette protéine est constitué de l'enchainement d'autant de codons. Toutefois, rappelons qu'en plus des codons, le gène inclut des introns et des indicateurs de début et de fin. On a également découvert d'autres indicateurs tels que l'opéron, qu'on évoquera dans la deuxième partie.
Revenons au principe du codage. Désigner un acide aminé par un code de 3 lettres est un procédé astucieux et simple. La nature, comme les êtres humains, emploie des langages pour communiquer. Toutefois, les langages de la nature et de l'univers semblent plus conformes à des codes symboliques, mathématiques ou géométriques qu'à la syntaxe du langage parlé humain (voir article Codes et rayonnements).
Le code de fabrication des acides aminés est le même pour tous les organismes vivants, du moins tant que l'on considère seulement l'ADN des noyaux. C'est l'un des fondements de l'unité biologique des êtres vivants. Qu'est-ce qui fait leur diversité? C'est d'abord la variété de la façon dont les codons sont combinés pour former les mots et les phrases, autrement dit les chromosomes.
Unité et diversité s'expriment aussi dans l'espèce humaine. Comment les individus peuvent-ils être à la fois tous semblables et identifiables en tant qu'humains, et uniques? L'ADN est presque le même pour tout le monde et c'est ce qui fait l'espèce humaine. Les individus de la même espèce ont le même plan de développement. Mais l'ADN comporte aussi quelques différences entre les individus sur certains loci.
Le génome humain compte 3 milliards de bases dont on estime que seulement 3 millions, soit 1 pour 1000, différent selon les individus. Toutefois ces
différences sont rarement localisées dans les séquences codantes. Ces différences semblent plutôt provenir de la façon dont ce code s'exprime sous
diverses influences, certaines fournies par les zones non-codantes.
Si notre évolution est dirigée par un programme de développement interne, le génotype, cela pose une question fondamentale de conscience. Quelle liberté avons-nous dans notre développement? Qu'est-ce qui est prédéterminé et qu'est-ce qui est malléable? Bien entendu, il s'agit du développement physiologique et physique.
Une partie de la réponse est que le mode d'expression de ce programme est éminemment variable. Pour nous en rendre compte, il suffit d'observer que toutes les cellules d'un individu possèdent le même ADN, le même génotype, et que pourtant les cellules se différencient dans le corps selon leur fonction. Ainsi les cellules du foie sont bien différentes des cellules de l'iris avec le même code génétique. L'explication est qu'il existe des facteurs dans la cellule qui contrôlent la façon dont ce code se manifeste. Même si les cellules ont le même potentiel, celui-ci s'exprime seulement partiellement, en fonction de son environnement.
On a retenu comme gènes les parties de l'ADN qui codent pour des protéines. Or il existe d'autres modes d'expression génétique inscrits dans l'ADN liés aux introns et aux autres zones non-codantes (voir 3e partie). Cette expression est modulée par des facteurs environnementaux (voir 2e partie). Que dire de notre développement émotionnel et mental? Nos pensées, nos émotions, notre conscience ont-elles une influence sur notre développement physique? Reconnaissons que nous ne savons pas grand chose de ces mécanismes et que nous devons garder une attitude humble.
La forme de la molécule d'ADN en double hélice est la forme qu'elle adopte le plus couramment dans les cellules vivantes. On la nomme ADN-B. Mais l'ADN bouge, se trémousse et prend parfois localement des conformations autres que ADN-B. On en a d'abord repéré dans des échantillons d'ADN hors des cellules, puis on en a repéré également dans les cellules vivantes.
L'hélice moléculaire d'ADN-B que nous avons étudiée est caractérisée par son sens d'enroulement à droite; et par son pas - c'est-à-dire la distance entre deux spires consécutives - de 3,32 nm, incluant 10,5 paires de bases. (voir article Spirales et hélices)
La molécule d'ADN-A est également une hélice qui s'enroule à droite. Mais les bases nucléiques y sont plus inclinées par rapport à l'axe de la double hélice, ce qui la rend plus compacte que l'ADN-B, avec un pas de 2,82 nm, et 11 paires de bases. On la trouve dans un milieu pauvre en eau, ou riche en sel, qu'on ne rencontre pas dans le vivant, mais dans les échantillons de matériel génétique utilisés en cristallographie aux rayons X.
La molécule d'ADN-Z est une une hélice qui s'enroule à gauche. Plus étirée, plus lâche, plus allongée, elle a un pas de 4,56 nm pour 12 paires de bases. Elle est constituée uniquement de bases C et G. On la trouve dans le vivant, dans les régions du génome où se produisent des réplications et des transcriptions. Elle y joue donc un rôle fonctionnel transitoire. De fait, une fois ce rôle achevé, elle se transforme en ADN-B.
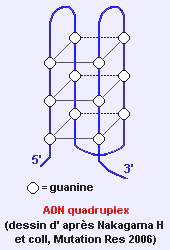
Il existe des endroits où l'ADN se fait des entorses, et où des brins s'associent par 3, accompagné d'un quatrième brin isolé. Cela est possible dans des séquences composées de motifs répétitifs et inversés. Ces séquences sont susceptibles de muter et se recombiner, de sorte qu'elles pourraient intervenir dans l'expression des gènes (voir article suivant l'ADN et ses modes d'expression)
Dans un quadruplex, ce sont 4 brins qui sont associés. C'est en fait 2 brins qui se sont repliés localement, là où les séquences sont riches en guanine (d'où leur nom de G4). Les bases de guanine se relient en plateaux carrés entre les 4 brins.
Cette conformation a été observée dans les cellules humaines en janvier 2013. Elle intervient dans les processus de transcription, épissage (voir article suivant l'ADN et ses modes d'expression), traduction, réparation d'ADN, mais aussi dans de nombreux processus cellulaires associés aux ribosomes par exemple, lors de la division cellulaire. La recherche indique que les quadruplexes sont plus susceptibles de se produire dans les gènes de cellules qui se divisent rapidement, comme les cellules cancéreuses. (Découverte de l’ADN à quatre hélices dans le génome humain, Gurumed, janvier 2013).
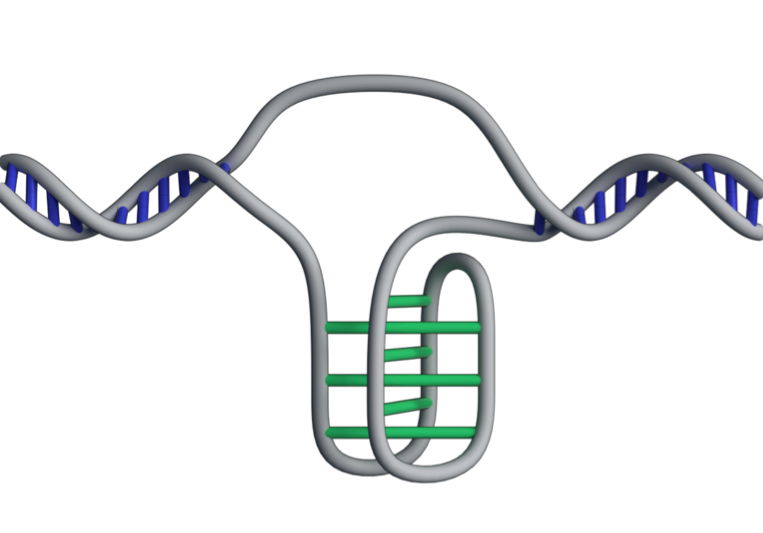
Une autre forme d'arrangement de l'ADN dans des cellules vivantes a été découverte en avril 2018 par des chercheurs australiens. C'est un nœud de l'ADN. Elle se concentre dans des parties qui ne codent pas pour les protéines, notamment les régions régulatrices qui activent et désactivent les gènes (voir article suivant l'ADN et ses modes d'expression).
 |
 |
 |
| De gauche à droite: ADN-A, ADN-B et ADN-Z. Merci à wikipédia |
ADN quadruplex. Merci à Atlas of
Genetics |
ADN I-motif (Zeraati et col Garvan
Institute) |
Sources: Wikipédia ADN B; ADN A; ADN Z, ADN G-quadruplex. Atlas of Genetics and Cytogenetics, ADN: structure moléculaire. Découverte de l’ADN à quatre hélices dans le génome humain, gurumed, 22 janvier 2013. Des chercheurs découvrent une nouvelle forme de notre ADN, gurumed, 24 avril 2018. Les i-motifs : cette nouvelle forme d'ADN enfin observée dans des cellules vivantes, Sciences et Avenir, 26 avril 2018.
DNA Structure: Alphabet Soup for the Cellular Soul, Pui Shing Ho Megan Carter, in book: DNA Replication-Current Advances, aout 2011. DNA triple helices: biological consequences and therapeutic potential, Aklank Jain, Guliang Wang, Karen M Vasquez,, Biochimie, 2008, 90, 8, 1117. QGRS-Conserve: A computational method for discovering evolutionarily conserved G-quadruplex motifs, Scott Frees, Camille Menendez, Matt Crum, Paramjeet S Bagga, Human Genomics, 2014, 8, 1, 8. Found: a new form of DNA in our cells, Garvan Institute, 24 avril 2018
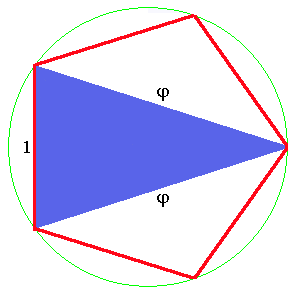
En recherchant la façon de diviser un segment en deux parties, dans une proportion telle qu'on peut la poursuivre indéfiniment sur les segments obtenus, on arrive à un rapport d’une valeur particulière appelée le nombre d’or ou section dorée. Plus précisément, on part d'un segment AB qu’on veut diviser en 2 segments de façon harmonieuse, AC et CB, telle que la proportion entre AC et CB soit la même que celle entre AB et AC. Autrement dit AC/AB = CB/AC = q
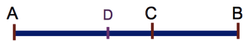
AC devient la nouvelle longueur à partager, entre AD et DC.
Ce qu'on nomme le nombre d'or φ est l'inverse de q: φ=1/q
Sa valeur est φ = (1+√5)/2 =1,618 et 1/φ=0,618
Le mathématicien Léonard de Pise, dit Fibonacci (le fils de Bonacci), a étudié la série de nombres qui porte son nom. Elle est construite à partir du chiffre 1 avec la règle que chaque terme de la suite est la somme des deux précédents.
0 - 1 - 1- 2 - 3 - 5 - 8 - 13 - 21 - 34 - 55 - 89 - 144 -
Or si on divise un terme par le précédent ou le suivant, on a une valeur proche du nombre d'or, d'autant plus proche que les nombres sont plus élevés. Dès les premiers termes 2 et 3, on s'en approche 3/2=1,5 ou 2/3= 0,66. C'est la proportion des 2/3. On va rapidement vers 1,618 avec 55/34=1,6176 (voir mes articles sur la spirale et sur la géométrie cristalline)
Il se trouve que le nombre d’or apparait 3 fois dans la molécule d’ADN-B, deux fois dans la vue longitudinale et une fois dans la vue axiale.
1- Revenons à la forme hélicoïdale telle qu’elle a été présentée dans le premier chapitre (reproduite colonne de gauche du tableau ci-dessous). On y remarque que le pas de l’hélice est de 3,4 nm et son diamètre de 2 nm. Ce diamètre correspond à la mesure entre les atomes de phosphore qui sont les plus massifs. Mais si on définit le diamètre par les atomes d’oxygène plus extérieurs, on obtient une valeur de 2,1 nm (voir DNA Structure and the Golden Ratio Revisited). Cela dessine un rectangle dont la longueur est de 3,4 et la largeur de 2,1 nm, soit un rapport de 1,619.
2- Une deuxième proportion dorée est révélée par l’emplacement mutuel des deux brins. Entre la première hélice et la deuxième hélice, se dessinent deux sillons, l’un plus grand que l’autre. Une façon précise de mesurer la distance entre les deux hélices est de repérer le même atome de phosphore dans les deux hélices (voir les ronds rouges de la deuxième colonne du tableau). Les deux distances sont de 2,06 and 3,38 nm avec un rapport de 1,64, proche de φ.
| |
 |
|
Merci à S.H Lasren |
3- Observons maintenant la double hélice B le long de l’axe (en section transversale). On y voit les deux chaines constituées des sucres (désoxyribose) et groupes phosphates alternés, enroulées en cercle, et les rayons du cercle formés par les paires de bases. Le nombre de paires de bases par pas (tour d’hélice) est de 10,5 dans l’ADN en solution, mais de 10 pour l’organisme dans le vivant (voir How many base-pairs per turn does DNA have in solution and in chromatin?). Dans ce cas, les rayons sont espacés par des angles de 36° environ, (pour 10 paires de base par pas), de sorte qu’ils s’inscrivent dans un décagone, qu’on peut décomposer en deux pentagones. Or la diagonale d’un décagone régulier est dans un rapport φ avec son côté.
 |
 |
 |
 |
|
ADN-B en coupe transversale Merci à Stéphane Despax |
Schéma de l’ADN-B en vue transversale Merci à Williams Chemistry |
ADN-B. Coupe transversale avec superposition d’un double pentagone Merci à S.H. Larsen |
Pentagone régulier où apparait le nombre d’or |
Sources: DNA Structure and the Golden Ratio Revisited, Stuart Henry Larsen, Symmetry, 2021, 13, 1949; The geometry of DNA: a structural revision, Mark E. Curtis, 1997; How many base-pairs per turn does DNA have in solution and in chromatin? Some theoretical calculations, Levitt M., Proc. Natl. Acad. Sci. USA, 1978, 75, 640; Une autre clé de l'ADN pour lutter contre l’arthrite, Jean-Claude Lambry-Inserm, 2013; Helical forms/images, Loren Williams.
Le principe d’un vaccin est de stimuler le système immunitaire pour que le corps soit mieux protégé contre une maladie déterminée. Pour cela on injecte l’agent pathogène (virus ou bactérie) à dose faible, pour obliger le système immunitaire à produire des anticorps spécifiques de cet agent. Ces anticorps seront encore présents pour défendre le corps d’une nouvelle attaque de cet agent infectieux.
On pense ainsi créer un moyen de protection en créant des gendarmes. En même temps, injecter un agent pathogène dans un corps saint n’est jamais inoffensif. Si cela protège d’une maladie, cela peut perturber ou dégrader d’autres fonctions. C’est ce qu’on nomme les effets secondaires.
En outre, en se concentrant sur une seule maladie, on ignore qu’il existe une immunité non spécifique, des mises en œuvre de stratégie du corps qui s’opposent à toutes les maladies ou attaques.
Malgré cela, on a multiplié le nombre de vaccins, en en créant pour de plus en plus de maladies. Les méthodes de fabrications ont aussi évolué. Au lieu d’injecter des virus entiers, on a injecté des fragments de virus, produits par des cellules cultivées en laboratoire.
Des vaccins sans agent infectieux sont apparus avec le développement du génie génétique. Ils se basent sur l'injection d’une protéine.
Avec les vaccins à ARN, on est passé à une étape au-dessus. Les protéines pathogènes ne sont plus cultivées en laboratoire mais fabriquées directement par les cellules du patient. Pour cela on lui injecte des molécules d’ARN synthétiques qui codent pour la fabrication d’une protéine spécifique (l’antigène). Dans le cas de la covid, il s’agit de la protéine spike, un morceau du virus SARS-COV 2. Cette protéine est nocive car elle ouvre la porte des cellules aux virus.
L’ARN doit être introduit dans le cytoplasme des cellules où il produit la protéine. Le système immunitaire régit en produisant des anticorps (une autre protéine).
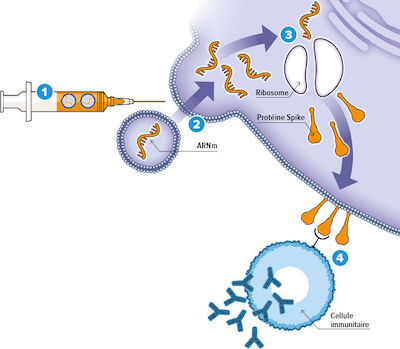
1 Capsule d’ARN
Le vaccin est constitué de fragments d’ARN messager enveloppés dans des bulles de lipides. Cet ARNm contient le plan de montage d’un morceau
caractéristique du virus, la protéine Spike.
2 Entrée de l’ARN dans la cellule
Après l’injection du vaccin,la capsule lipidique fusionne avec la membrane de la cellule humaine. Ainsi l’ARNm est déversé dans la cellule.
3 Production des protéines spike
Les ribosomes, qui sont les « usines à protéines » de la cellule, lisent l’ARNm et fabriquent les protéines Spike. Dans les heures qui
suivent, l’ARNm est détruit. Les protéines produites migrent à la surface externe de la cellule.
4 Réponse immunitaire
À l’extérieur, certaines cellules immunitaires repèrent les protéines Spike, s’y attachent et produisent des anticorps. D'autres cellules
interviendront pour la mise en mémoire. Ainsi notre système immunitaire apprend à reconnaître et à lutter contre Spike et sera prêt à contrer le vrai
virus Sars-Cov2 en cas de future infection.
Merci à Que choisir
Le problème avec l’ARN, qui est fait d’un seul brin, contrairement à l’ADN fait de deux brins, c’est qu’il est très instable et se dégrade rapidement sans atteindre le cytoplasme protégé par la membrane cellulaire. C’est pourquoi les laboratoires fabriquent une enveloppe pour la molécule d’ARN, enveloppe faite de particules de graisse (lipidiques). Il s’agit en définitive d’un virus artificiel.
Dans le cas de la covid 19, il reste des mystères sur la nature de la protéine Spike fabriquée. Selon K. Kingston, ex-vice présidente de Pfizer, il s’agirait plutôt d’une nanoparticule lipidique magnétisée (MPEG) qui, en pénétrant dans la cellule, a la capacité de modifier la biologie cellulaire, créer des virus et contrôler les signaux du système nerveux (plus de détails dans la vidéo de Stew Peters, Covid-19 pas un virus).
Sources: Comment fonctionnent les vaccins à ARN (et à ADN)?, Bruno Pitard, The conversation, 26/11/2019; Vaccins à ARN sur Wikipedia; Vaccin: l'ARN messager, un espoir dans la lutte contre les autres maladies ?, Jérome Florin, RTL, 13/05/2021
Accéder aux autres parties:
Texte conforme à la nouvelle orthographe française (1990)
25 septembre 2008- dernier ajout février 2023 (annexe nombre d'or - vaccin ARN)
{kind=link}